Pandas Series value_counts returns a series of count of unique entries present in that series.
sort:By default True will sort by values if False will return count of values as per entries in series.
ascending: Sort in ascending order By default False if True will return output as ascending orders by count of values.
normalize:By default False If True will compute histogram for values or group them in certain intervals or ranges as in histogram.
bins=none, integer ,optional Rather than count values, group them into half-open bins.
dropna:By Default True, Don not include counts of NaN (np.nan) values.If False will return count of NaN value.
How to use pandas series value counts:
Example of code shown below
#import pandas and numpy libarary
import pandas as pd
import numpy as np
#from panda import series and data frame
from pandas import Series,DataFrame
# create a series alphabetic and numeric
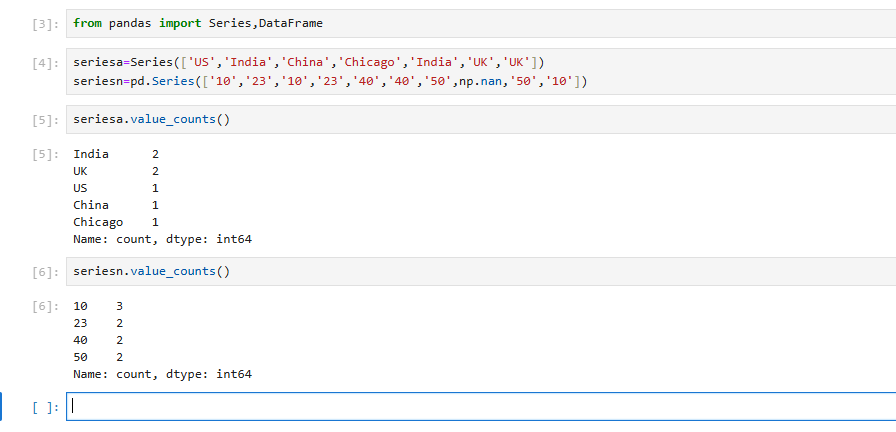
seriesa=Series(['US','India','China','Chicago','India','UK','UK'])
seriesn=pd.Series(['10','23','10','23','40','40','50',np.nan,'50','10'])
#print series
seriesa
0 US
1 India
2 China
3 Chicago
4 India
5 UK
6 UK
dtype: object
# series pandas value counts apply
seriesa.value_counts()
India 2
UK 2
US 1
China 1
Chicago 1
dtype: int64
#print series
seriesn
0 10
1 23
2 10
3 23
4 40
5 40
6 50
7 NaN
8 50
9 10
#series value counts apply
seriesn.value_counts()
10 3
23 2
40 2
50 2
dtype: int64