To extract text from a PDF using Power Automate, you can use the “Microsoft Power Automate PDF Connector” along with the Power automate Convert PDF to Text action for normal PDF.But for scanned PDF or OCR PDF in power automate you have to make flow in cloud flow here’s a simple guide to achieve this:
Steps for Power automate Convert PDF to Text:
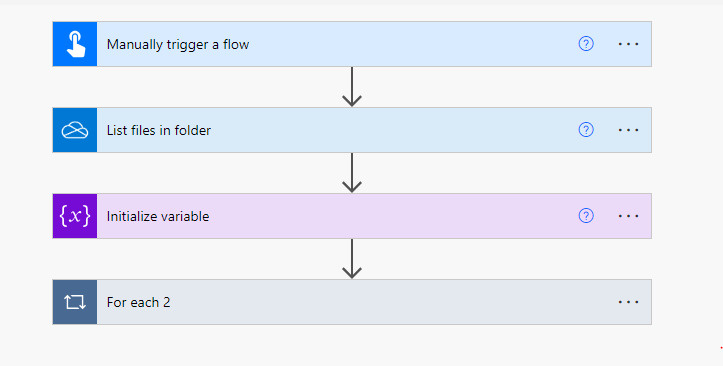
- Start by creating a new flow in Power Automate.
- Manually Trigger a file or You can choose a trigger for your flow, such as “When a file is created (SharePoint)” if your PDF file is stored in SharePoint, or “When a file is created (OneDrive)” if it’s stored in OneDrive.
- Add an action and Serach for “Get file content Using Path”. and provide path of file in parameters section.
- Add another action “Recognize text in an image or a PDF document” and provide “filecontent” as parameter.
- Initialize variable and input Name “text”, type string.
- For each 1 “body/response” for each “lines” “Append to string variable” input “text”
- Then “Create File” action and Input Path,File name and text as file content.
- Save and test your flow to ensure that the text extraction from the PDF is working as expected.

This approach allows you to automate the extraction of text from PDF files using Power Automate.Your file is converted into text.
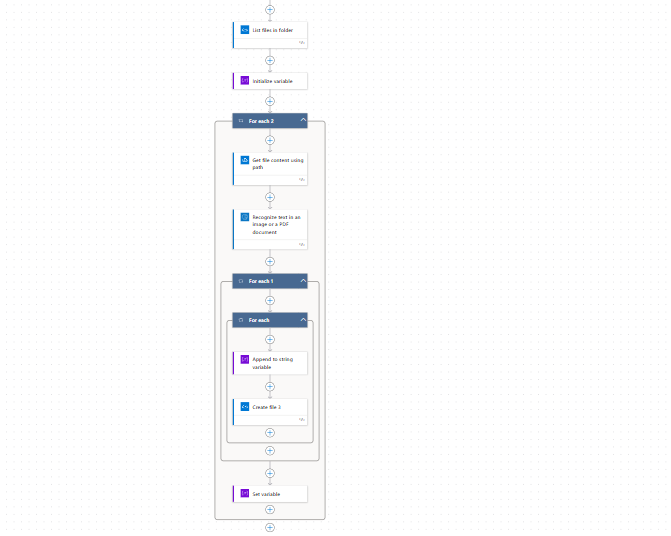
Flow to Convert PDF to Text file in folder:
Above flow will only convert one PDF file to text .If we have hundreds of PDF file to which we want to convert PDF to text to begin with:
- We need to list all files in folder for this we will use “List files in folder” action and provide path of folder where all files exist.
- Initialise variable action.Name is equal to Text and type is equal to string.
- Inside for loop Get file content using path action.File is equal to path from previous path.
- Recognise text in a image or a PDF document connector is used.Image is equal to file content.
- Then again inside loop Append to string variable.Name and value is equal to text
- Create file connectors is used.file name name without extension and file content text.
- Set variable value to Zero.In name select text and in value select zero.